
Stop Missing Context: Building Reliable Hybrid Search in PostgreSQL
Authors:
Vivek Krishnamoorthy
![]() ,
M Harshavardhan Reddy
,
M Harshavardhan Reddy
![]() ,
and Sai Suraksha Patnam
,
and Sai Suraksha Patnam
![]() .
Published on 10/22/25
.
Published on 10/22/25
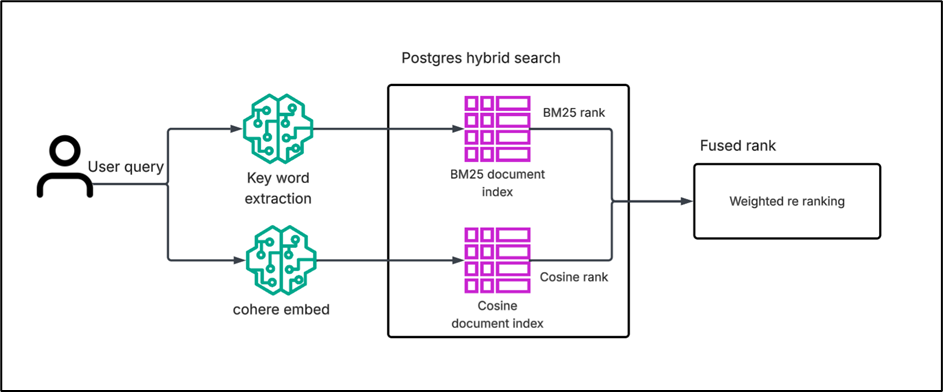
What is Hybrid Search
Hybrid search is a way of improving search results by combining two different approaches: keyword-based search (like BM25) and vector-based search (cosine similarity). Keyword search is good when the query and the document share the exact same words, but it fails when synonyms or different wording is used. On the other hand, cosine similarity looks at the meaning of the text, so it can connect queries and documents even if they don’t use the same words. The problem is that cosine sometimes gives results that are related in meaning but not exactly what the user is asking for. By fusing both approaches, hybrid search balances keyword precision with semantic understanding. This helps in getting more accurate and relevant results compared to using only one method.
What is a vector
In modern databases and applications, a vector is a numerical representation of data, like text or images. Think of it as a list of numbers that, while seemingly random on their own, collectively describe the unique characteristics of an item. For example, a picture of a cat could be converted into a vector where the numbers represent its fur color, whisker length, and ear shape. This process, known as embedding.
Now, why do we even need vectors? Because they make it possible to compare complex data in a simple, mathematical way. Instead of just saying “two texts are similar” based on exact words, vectors allow us to measure how close or far apart they are in the meaning.
Vector types in pgvector
vector (float32)
- Full precision embeddings (4 bytes per dim).
- Use: Best default when you care about accuracy over storage
- Dims: store up to 16k, index up to 2k.
halfvec (float16)
- Half precision embeddings (2 bytes per dim).
- Use: Large-scale embeddings where speed + storage savings matter.
- Dims: store up to 16k, index up to 4k.
bit (binary)
- Compact binary vectors (1 bit per dim).
- Use: Quantized or binary embeddings for ultra-efficient storage.
- Dims: index up to 64k.
sparsevec (sparse float)
- Stores only non-zero values.
- Use: High-dim sparse data like TF-IDF or bag-of-words.
- Dims: store up to 16k non-zeros, index up to 1k non-zeros.
What is a Vector Database
A vector database is a type of database designed to store, manage, and search vectors (embeddings). vector databases are built to handle similarity search — is the process of retrieving the closest vectors to a query vector, based on a chosen distance or similarity.
Widely Used Vector Databases
1. Postgres with pgvector
Postgres isn’t originally a vector database, but with the pgvector extension, it becomes one. This means you can store and search vectors alongside your regular relational data the biggest advantage is that you don’t need a separate system.
2. Pinecone
Pinecone is a fully managed, cloud-native vector database. It’s built specifically for similarity search at scale, meaning you can quickly find relevant items across millions of embeddings.
3. Chroma
A user-friendly, open-source vector database built with developers in mind. It works great for AI-powered apps like chatbots and recommendation tools and lets you store and query embeddings easily.
4. Qdrant
Built in Rust for high performance and efficiency, Qdrant excels at similarity search with advanced filtering features like combining metadata constraints with vector queries.
Why Choose Postgres with pgvector
Among the many options for vector databases, Postgres with pgvector offers a compelling choice worth exploring. Postgres is already one of the most widely used databases in the world. It’s stable, open-source, and trusted for all kinds of applications from small startups to big enterprises.
Using pgvector we don’t have to manage a separate database just for embeddings. We can keep our traditional relational data (like users, products, logs) and vectors (like text or image embeddings) all in one place.
Most vector databases (like Pinecone, Weaviate, Milvus, Qdrant, etc.) are specialized systems one might need to run two databases side by side:
- One for your regular relational or document data.
- Another a vector database just for embeddings and similarity search.
When it comes to text search, there are two common approaches we have used:
Below we demonstrate the process of enabling the pgvector extension, creating tables to support both BM25 and cosine similarity searches, inserting data into these tables, and finally performing efficient retrieval operations using these search methods. The code connects to the database with psycopg2, prepares SQL insert statements, and stores both raw text and vector representations for later retrieval and semantic search.
- Install Extension: create extension pg_search;
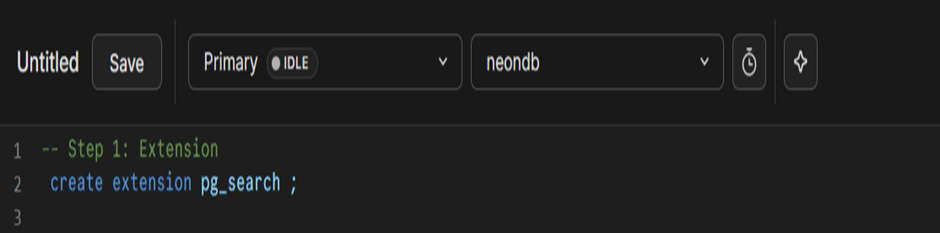
Fig 1: Creating pg_search extension in postgres
BM25
For traditional keyword search, BM25 is often used. It ranks documents based on how often and where the query terms appear, which makes it great when exact keyword matching is important.
- Why are we using BM25
When a user enters a query, BM25 looks at the words in the query and compares them with the words in our stored pages. It gives higher scores to pages where the query words appear more frequently and where those words are considered important. To make this process more effective, we store each page as a single chunk instead of breaking it into smaller pieces. This ensures that BM25 can match keywords across the entire page without losing context. In our project, we are using pg_search, which allows us to implement BM25 keyword-based search efficiently on PostgreSQL. Because of this, BM25 is very reliable for quickly identifying pages that contain the exact words the user is looking for, making our search system accurate and efficient.
The scores that BM25 gives are good for ranking pages, but the problem is that these values don’t follow any fixed range. They can go high or low depending on the type of query and the page content. To make these scores easier to read and to keep them consistent with the other methods we use in the project, we normalize the BM25 results. What this means is, we take the page with the highest score and mark it as 1, the lowest as 0, and then adjust all the other scores in between. For example, if one page gets highest score as 13.1 and another gets lowest score as 8.4, after normalization they will be shown as 1.000 and 0.000, and the rest will fall in between these two.
This way, the BM25 scores are not only showing the keyword relevance but are also easy to compare and understand. It keeps the results clear, consistent, and still reliable for keyword-based matching.
- Define the table to store the text chunks
The below snippet is creating a table named ew_text_embeddings_bm25 to store text chunks and related metadata. It defines columns for document details, page number, text content, and car model information, with id as the primary key.
CREATE TABLE IF NOT EXISTS rag.new_text_embeddings_bm25 (
id SERIAL PRIMARY KEY,
document_name TEXT,
page_number TEXT,
element_text TEXT,
car_model_name TEXT,
car_model_year TEXT
);
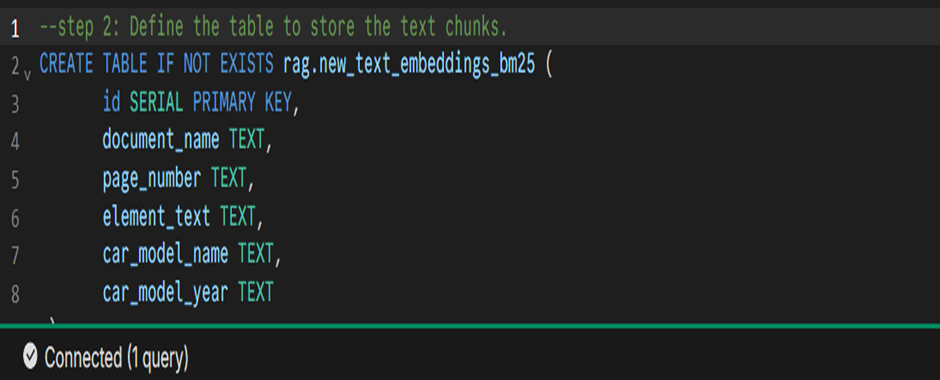
Fig 2: Create statement of BM25 table
- Create the bm25 index on the new `element_text_vector` column.
The below SQL command creates a BM25 index on the element_text column of the summary_chunks_bm25 table. The index improves text search performance by ranking results based on relevance using the BM25 algorithm.
CREATE INDEX element_idx6 ON rag.new_text_embeddings_bm25
USING bm25 (id, element_text)
WITH (key_field=id);
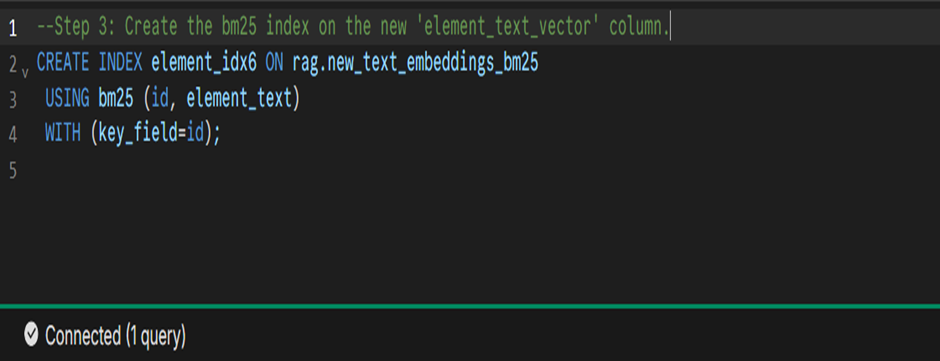
Fig 3: Creating index for BM25
- Inserting BM25 text embeddings into the database

Fig 4: inserting text embeddings for BM25
The above code snippet uses psycopg2 to insert text data into the new_text_embeddings_bm25 table in a Postgres database. It connects to Neon, executes the SQL insert command with document details.
- Query – BM25
The below query performs a BM25 keyword search on the new_text_embeddings_bm25 table to find the most relevant text chunks about the 2024 Tacoma hybrid powertrain. The results return document name, page number, and a relevance score, ordered from highest to lowest.
SELECT
document_name,
page_number,
element_text,
paradedb.score(id) AS score
FROM rag.new_text_embeddings_bm25
WHERE element_text @@@ ‘2024 TACOMA hybrid power train’
AND car_model_name @@@ ‘TACOMA’
AND car_model_year @@@ ‘2024’
ORDER BY score DESC
LIMIT 10;
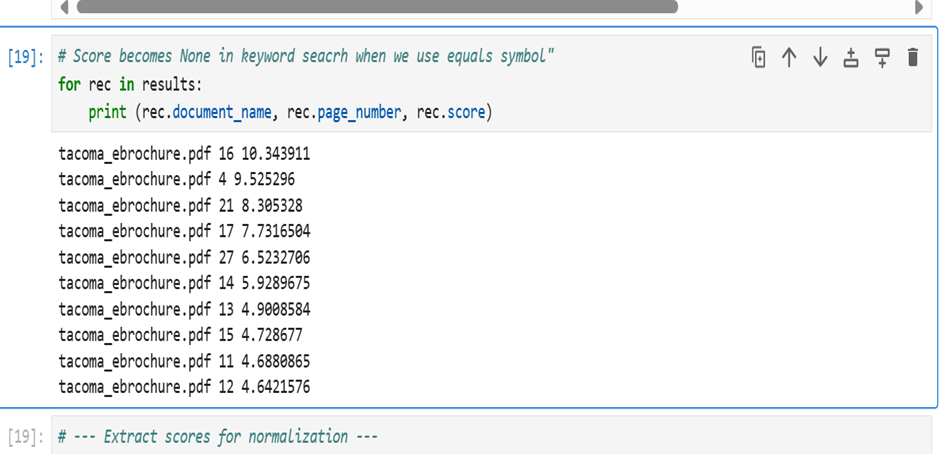
Fig 5: BM25 Search result
Cosine Similarity
For semantic search, cosine similarity is more accurate. It compares the cosine angle between two vectors (ignoring their length) to measure how similar they are in meaning — perfect for working with embeddings.
Why are we using Cosine Similarity
Cosine similarity is a mathematical technique used in search how similar two vectors. In our project, these vectors come from embeddings of text chunks. First, we create a summary for each page using the Qwen2.5-VL-32B.
Qwen2.5-VL-32B’s visual understanding lies the integration of advanced Vision Transformers (ViTs). By leveraging ViTs, the model can process and interpret complex visual elements such as images, charts, and tables with high precision. This architecture enables the model to seamlessly combine visual features with textual context, leading to richer multimodal reasoning capabilities. Through this design, Qwen2.5-VL-32B not only generates accurate summaries of visually rich documents but also delivers more detailed and context-aware responses to user queries. (Reference to Harsha Blog)
Then we split the summary into smaller parts, called chunks. Each chunk is turned into an embedding using the Cohere model. When we run a search, the query is also converted into a vector. Cosine similarity is then used to compare the query vector with the chunk vectors and see which one is similar. This makes it very useful for semantic search, because it can find content that is related in meaning, even if the words are not same.
- Create statement for Cosine table
The below SQL command creates the new_summary_embeddings table to store text summaries, metadata, and associated embeddings. It includes a VECTOR(1024) column for vector representations, enabling semantic search alongside traditional data.
CREATE TABLE IF NOT EXISTS rag.new_summary_embeddings (
id SERIAL PRIMARY KEY,
document_name TEXT,
page_number TEXT,
element_summary_text TEXT,
car_model_name TEXT,
car_model_year TEXT,
element_summary_embedding VECTOR(1024),
chunk_id TEXT,
image_path TEXT
);
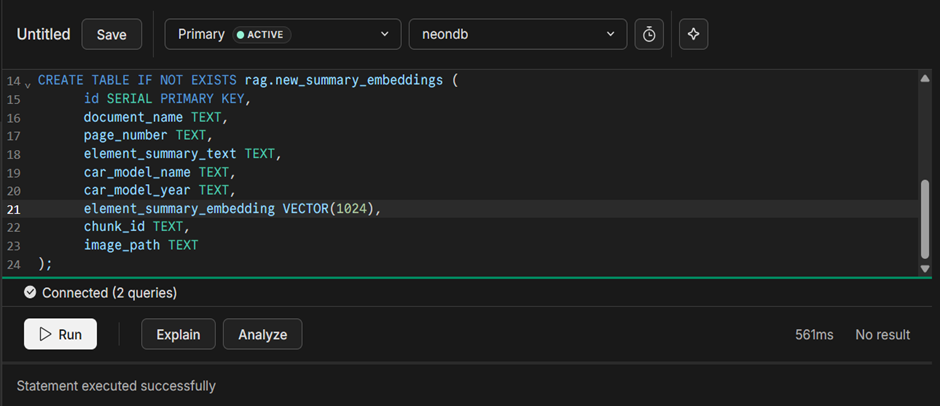
Fig 6: Creating table for cosine
- Inserting vector embeddings into Cosine table
Here, we demonstrate how the converted vectors were stored in our database table.
The below code snippet has a function get_text_embedding() that generates an embedding vector for a given text using Cohere’s embed-english-v3.0 model.
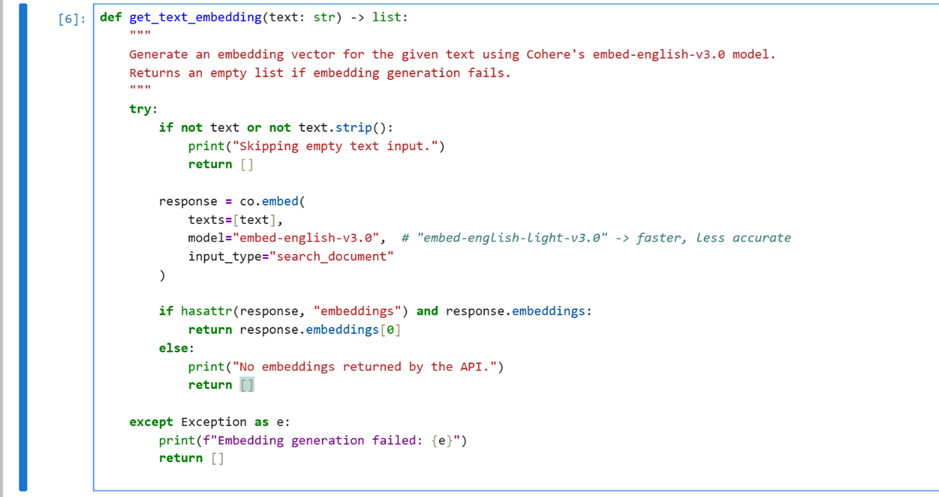
Fig 7:using cohere model to generate embedding
The below code snippets use the psycopg2 library to connect to a PostgreSQL database and insert data. It’s executing an INSERT statement to store a new element, which includes text and its corresponding vector embedding, into the rag.new_summary_embeddings table.
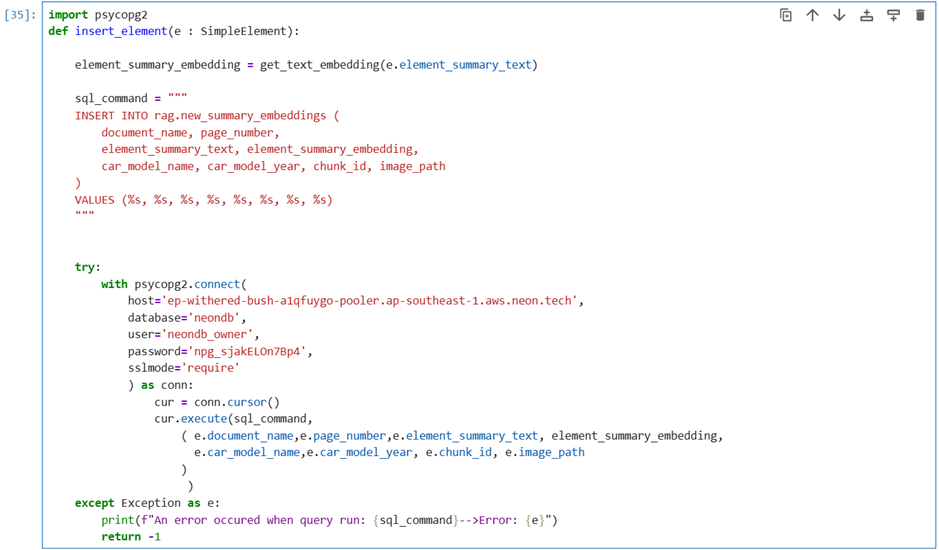
Fig 8: Inserting summary embeddings for cosine
- Query – Cosine
The below SQL query performs a vector similarity search. It selects elements from a database table, calculating the cosine similarity between an embedded query and stored embeddings. The results are ordered to find the 50 most relevant “TACOMA” documents from 2024.
SELECT id, document_name,page_number, element_summary_text, element_summary_embedding <=> %(embed_query)s::vector as cosine
FROM rag.new_summary_embeddings
WHERE car_model_name = ‘TACOMA’ and car_model_year = ‘2024’
ORDER BY cosine
LIMIT 50;
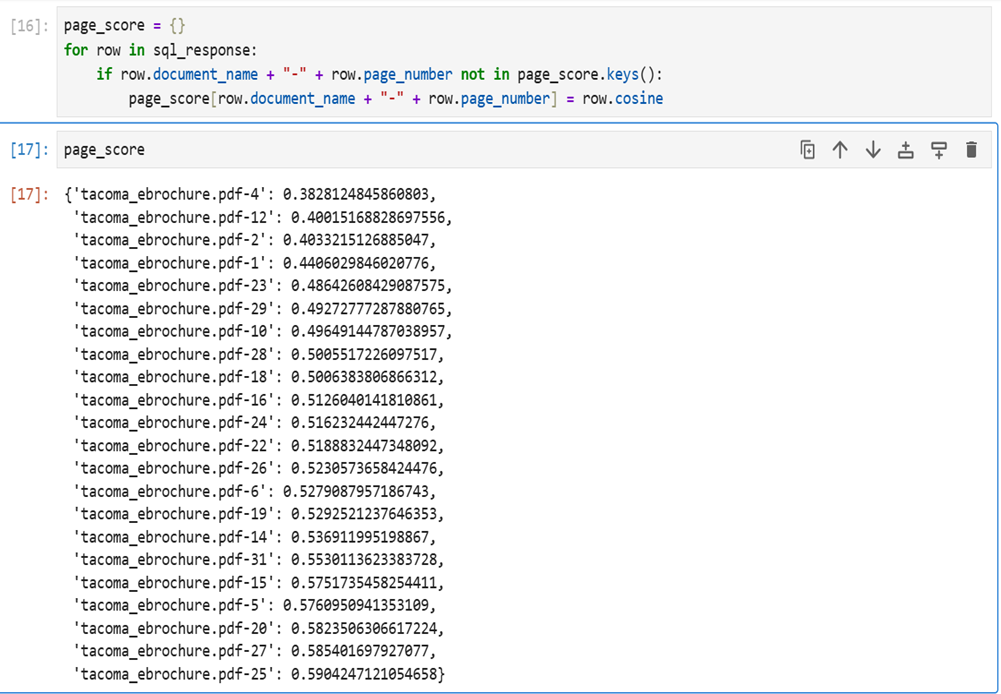
Fig 9: Cosine search result
Fuse Ranking
Fused ranking is a way of combining results from different search methods into one final list. For example, BM25 works well for finding exact keyword matches, while cosine similarity is good at finding results based on meaning. Instead of depending on just one, fused ranking combines the outputs of both and reorders them in a balanced way. This helps make sure the final search results include pages that match the exact words as well as those that are similar in meaning, giving more accurate and helpful results.
Why we are doing Fused Ranking in Hybrid Search
In our project, the aim is to build a search system that gives the best and most accurate results to the user. If we depend on only one search method, it won’t always work well because each method has its own limitations. For example, BM25 works well when the query matches the same keywords in the page, but it struggles when the words are different even though the meaning is the same. On the other side, cosine similarity works well for finding meaning, but sometimes it misses out on the importance of exact keywords.
To solve this, we are using Hybrid Search, where both methods are applied together. BM25 is used for keyword-based matching, and cosine similarity is used for meaning-based matching. But just having two sets of results is not enough—we need to combine them into one final list. That’s where Fused Ranking comes in. Wetake the scores from BM25 and cosine similarity, give weight to each (in our case 70% BM25 and 30% cosine similarity), and then merge them to prepare a single ranked output.
We decided to keep 70% weight for BM25 and 30% for cosine. The reason is, in most of the queries users give, the exact keywords matter a lot for getting the right result. BM25 is good at catching those exact words, so we gave it higher weight. But sometimes the user might type the query in a different way or use similar words, so we also wanted to consider the meaning. That’s why we added cosine similarity with 30% weight. By combining both like this, the results will have both keyword accuracy and meaning-based relevance.
By doing this, our system captures both exact keyword matches and the meaning behind the query in one place. This makes the final search results much more reliable and useful for the user. That’s the reason we are doing Hybrid to Fused Ranking in our project.
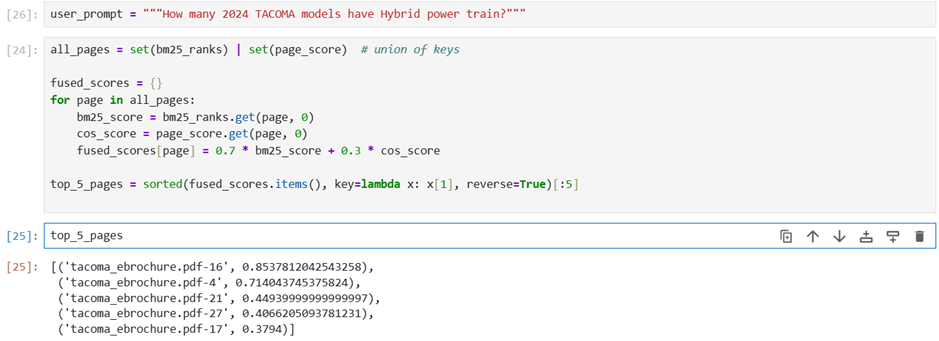
Fig 10: Fused Ranking of Document Pages using BM25 and Cosine Similarity
In this blog we have explained how to perform Hybrid Search in postgres by Combining Cosine Similarity and BM25 through Fuse Ranking and how postgres with pgvector & pg_search extensions can be used to store and retrieve vectors efficiently.