
The Future of Complex Document Workflows: Can VLMs Bridge Vision and Language?
Authors:
Vivek Krishnamoorthy
![]() ,
M Harshavardhan Reddy
,
M Harshavardhan Reddy
![]() ,
and Jathin Sai Manvi on 09/23/25
,
and Jathin Sai Manvi on 09/23/25
Vision-Language Models (VLMs)
A Vision-Language Model (VLM) is designed to process and understand information that combines both text and visual elements such as images, charts, tables, diagrams, or even video frames. Unlike traditional language models that only handle text, VLMs can interpret visual context alongside natural language, making them highly effective for tasks like:
- Document understanding from PDFs, scanned images, or forms.
- Generating image captions for accessibility.
- Visual question answering (VQA).
- Multimodal summarization combining text and figures.
- Enhancing search and retrieval systems by indexing both text and visuals.
- Assistive AI applications for visually impaired users.
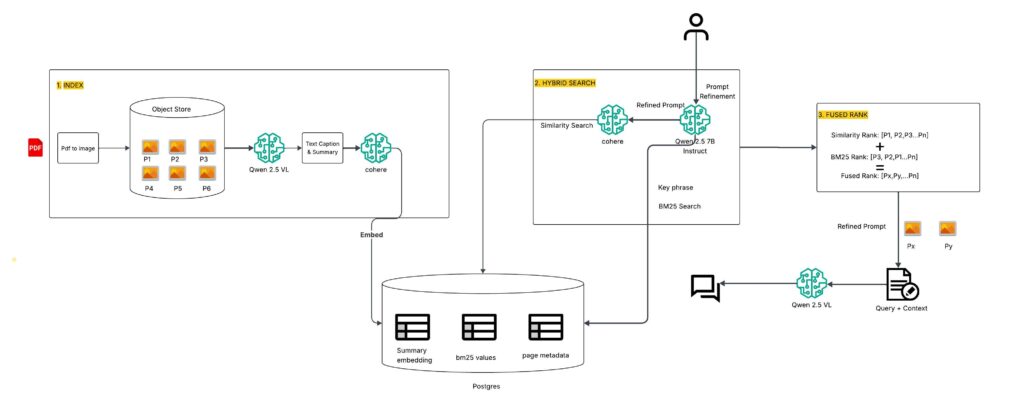
Fig. 1 Architecture
In the above diagram, you can see that instead of collecting detailed metadata like document trees, chunk order, references, or bounding boxes, the system can directly provide the PDF pages to a VLM. Since a VLM processes both text and visuals together, the document itself becomes the context for the model.
With VLMs, we no longer face the challenge of manually building metadata from complex layouts of text, tables, and images. The model can interpret charts, figures, and text inline without requiring extra parsing pipelines. This avoids errors from misaligned formatting or broken ordering and makes the process of handling mixed content simpler and more dependable.
We initially implemented Hybrid Search using a weighted score of 0.7 * BM25 + 0.3 * cosine similarity, giving more weight to keyword relevance while still incorporating semantic meaning. As we assessed with several types of user prompts, we also experimented with other BM25–cosine weight combinations to see how retrieval quality and accuracy could be improved.
Vision-Language Models (VLMs) address this by treating the entire PDF page as context, directly interpreting both text and visuals in a unified way. This reduces preprocessing needs and enables more accurate, context-aware document understanding.
How VLMs can be Superior to LLMs In Understanding Documents
Vision Language Models (VLMs) can be superior to traditional Large Language Models (LLMs) in answering user queries because they are capable of understanding and processing not just textual content but also visual elements like images, charts, and tables, which are often present in real-world documents such as PDFs and other such files.
While LLMs are restricted to textual data and may miss context contained in visual information, VLMs bridge this gap by jointly analyzing both mediums, enabling them to generate richer, more accurate summaries and insights for enhanced understanding.
This multimodal understanding allows VLMs to capture details that LLMs cannot, such as extracting meaning from diagrams or interpreting images alongside text, ultimately leading to more comprehensive and reliable answers based on the context that we provide.
In our architecture, we leveraged Qwen2.5-VL-72B and Qwen2.5-VL-32B to generate summaries of each PDF page. Its ability to interpret both text and visual content, including tables and charts, provided richer and more accurate summaries than a text-only model could achieve.
Models used…
- Qwen2.5-7B-Instruct – Prompt Refinement and Key Phrase Extraction
- Qwen2.5-VL-32B-Instruct-AWQ – Summary Generation
- Cohere embed-english-v3.0 – Embedding the Generated Summary
Qwen2.5-7B-Instruct
Qwen2.5-7B-Instruct is a 7-billion parameter large language model fine-tuned for tasks such as prompt understanding, rewriting, and extracting relevant information. It is designed to handle natural language queries effectively by identifying intent, parsing input, and generating well-structured and meaningful responses that are contextually appropriate.
Compared to larger models, the 7B version is relatively lightweight and highly efficient, which makes it well suited for fast preprocessing tasks and intermediate steps that do not require extremely heavy computational overhead. This balance between performance and efficiency ensures that it can be integrated smoothly into real-world applications.
In our system, we used Qwen2.5-7B-Instruct specifically for prompt refinement. Whenever a user enters a query, the model extracts the most important keywords or phrases that represent the user’s intent. For example, from the query “How many Tacoma models have the hybrid powertrain?” it refines the input to the key phrase “hybrid powertrain.” This step ensures that subsequent processing is focused on the essential concepts, improving both accuracy and efficiency in retrieving relevant information from the knowledge base.
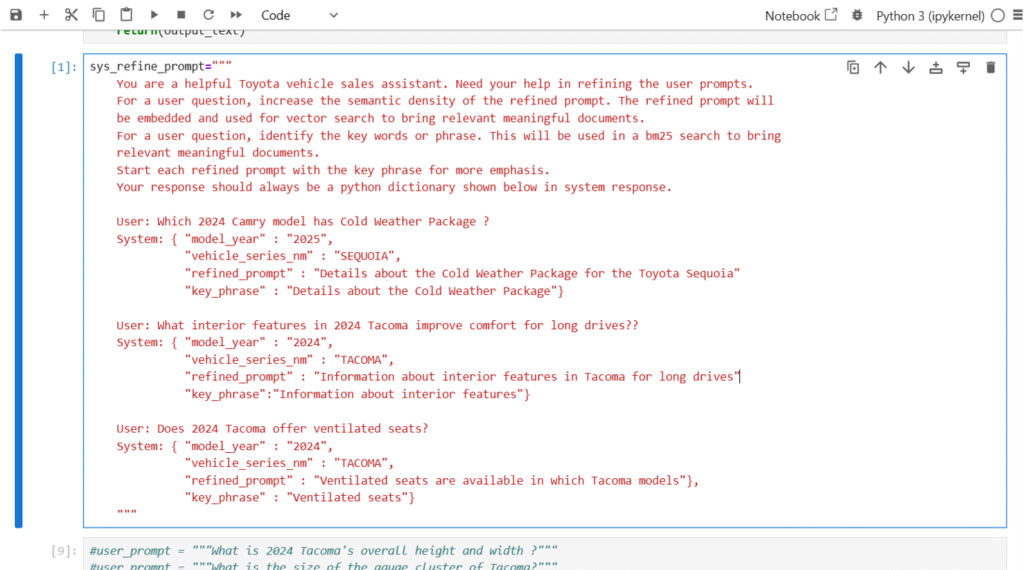
Fig 2: System Prompt for Qwen2.5-7B
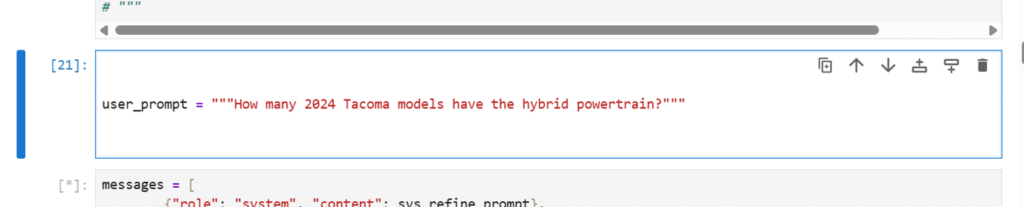
Fig 3: User Prompt
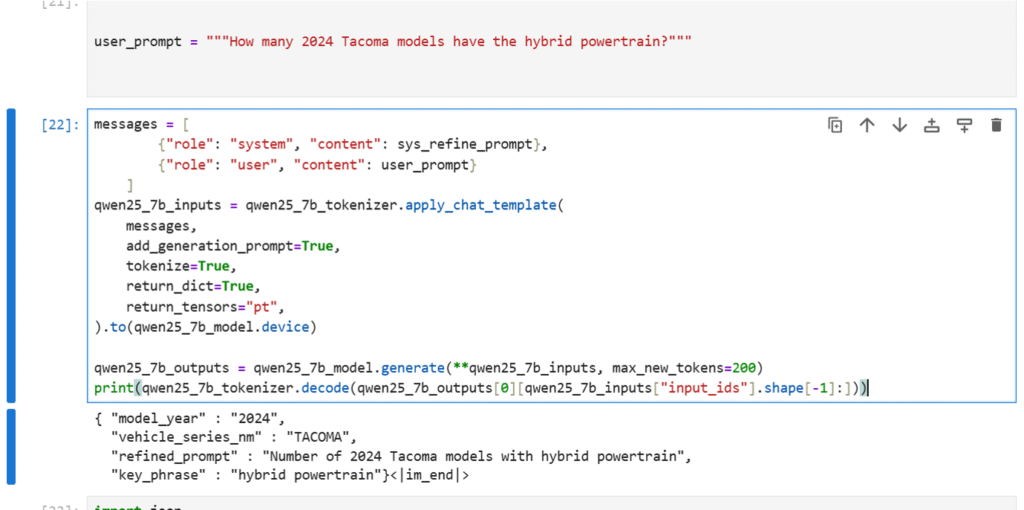
Fig 4: Prompt Refinement and Key Phrase Extraction
Here you can observe how the Qwen 7B Instruct model extracted the key phrases from the user prompt. These key phrases will later be used in the afore mentioned hybrid search for BM25 key search.
Qwen2.5-VL-32B-Instruct-AWQ
Qwen2.5-VL-32B-Instruct-AWQ is a large vision-language model (32 billion parameters) capable of understanding and generating summaries from multimodal inputs including text, images, tables, and charts. Its strength lies in interpreting complex documents with mixed content, making it highly effective for scenarios where structured and unstructured data coexist.
The “VL” variant ensures it can process visual and textual elements together, and the AWQ quantization enables more efficient inference on large-scale deployments.
We used this model for summary generation of PDF pages. Unlike regular text-only models, the VL model goes beyond plain text extraction—it captures meaning from diagrams, tables, and images alongside written content. This allowed us to generate rich, structured summaries for each page of a document. Along with generating summaries, we also used this model to directly answer user questions, leveraging its ability to combine text and visual understanding for accurate and context-aware responses.
At the core of Qwen2.5-VL-32B’s visual understanding lies the integration of advanced Vision Transformers (ViTs). By leveraging ViTs, the model can process and interpret complex visual elements such as images, charts, and tables with high precision. This architecture enables the model to seamlessly combine visual features with textual context, leading to richer multimodal reasoning capabilities. Through this design, Qwen2.5-VL-32B not only generates accurate summaries of visually rich documents but also delivers more detailed and context-aware responses to user queries. For more details on the role of Vision Transformers in our model, please refer to the official link provided in the references section.
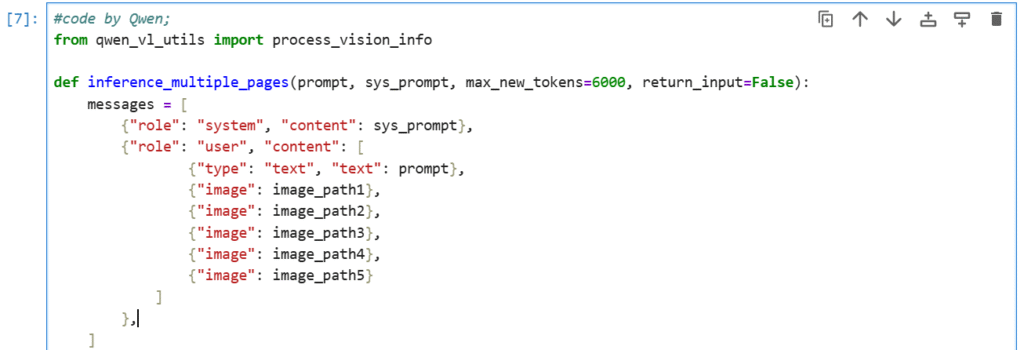
Fig 5.1: Inferencing multiple document elements

Fig 5.2: Inferencing multiple document elements

Fig 6: Answer generated by the model
Here you can see how the model generated an answer to the user prompt shown in Fig. 3. By interpreting both the textual content and the visual elements of the document, the Vision-Language Model was able to understand the query in context and produce a detailed, accurate response. This demonstrates the model’s ability to go beyond simple text matching and instead reason across multiple modalities to deliver meaningful answers.
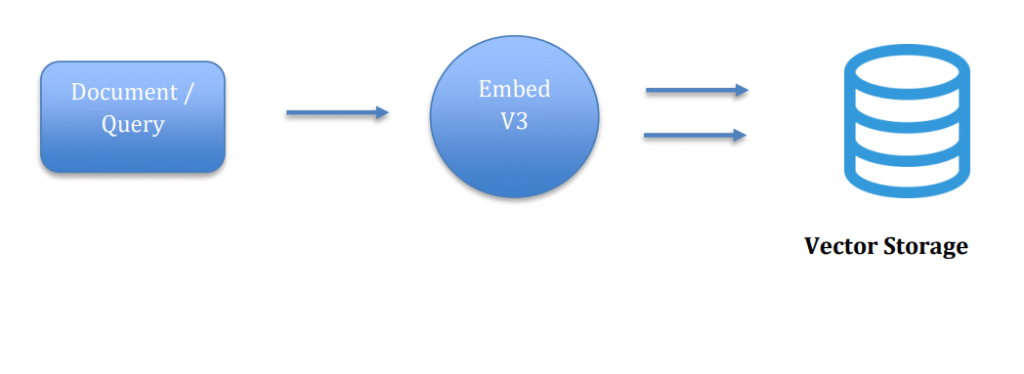
Cohere embed-english-v3.0
Cohere embed-english-v3.0 is a state-of-the-art embedding model that converts text into high-dimensional vector representations. These embeddings are designed to capture semantic meaning, allowing similar concepts or sentences to be represented close to each other in vector space for improved understanding and efficient data retrieval.
Cohere’s embedding models are optimized for retrieval and semantic search, making them a popular choice in building MultiModal-RAG (Retrieval-Augmented Generation) systems and intelligent databases. Cohere introduced the input_type parameter for embeddings so that queries and documents can be encoded differently, ensuring each is optimized for its role. By distinguishing between search_query and search_document, the model produces embeddings that align more effectively, leading to more accurate and relevant results.

Fig 7: Embedding the generated summaries.
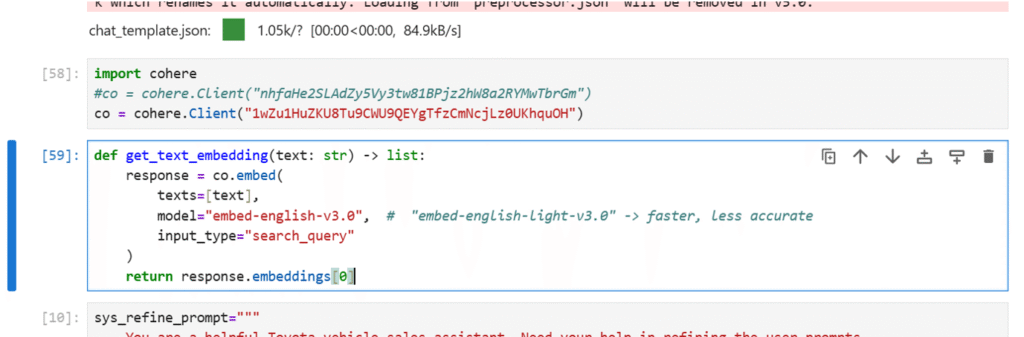
Fig 8: Embedding the User’s prompt.
In our project, we used Cohere embed-english-v3.0 to convert the generated summaries into embeddings and store them in the database. This step enabled efficient semantic search whenever a user asked a question. Instead of relying on keyword matches itself, the system could compare the vector representation of the user’s refined query (from the 7B model) against stored vectors of page summaries. This ensured that the most relevant information was retrieved quickly and accurately, forming the basis for high-quality answers.
Example Document
Fig 9: Example Document Screenshots


The above screenshots depict how a document can contain multiple elements such as text, tables, and images, all combined within a single layout.
Test Results

These are the test results we obtained after evaluating each type of element present in the document. The analysis covers text, tables, and images, providing insights into the model’s performance across different content formats.
Below are selected responses generated by the Qwen2.5-VL-32B-Instruct-AWQ model. These examples provide a clearer understanding of the model’s approach to addressing user prompts and demonstrate its response patterns across different input types.

Fig 10: Answer generated by the model for the user prompt for a text-based question.

Fig 11: Answer generated by the model to a user prompt for a table-based question.
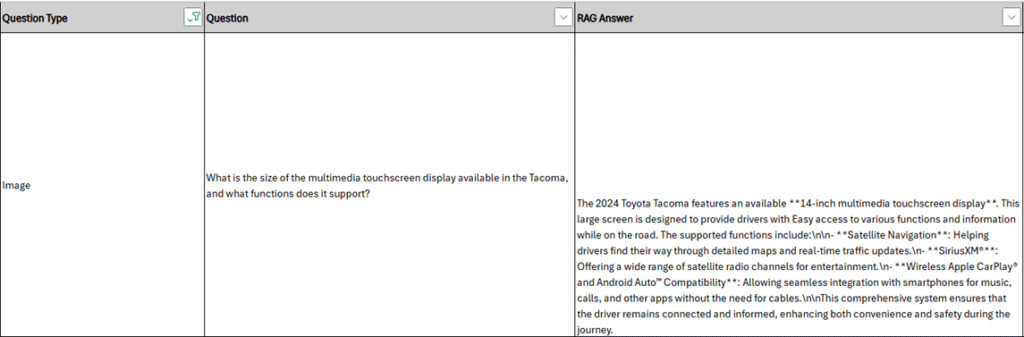
Fig 12: Answer generated by the model to a user prompt for an image-based question.
You can observe how the model is attempting to understand the user’s question by analyzing all the relevant textual and non-textual information present in the document before reaching a conclusion and providing an answer. This process highlights the model’s capability to integrate multiple elements effectively to generate accurate and context-aware responses.