
Text-to-SQL Performance: A Head-to-Head Comparison of Llama 3.1, Qwen 2.5, and GPT-4.5 Turbo
Authors: Vivek Krishnamoorthy ![]() , M Harshavardhan Reddy
, M Harshavardhan Reddy ![]() , and Purandeswari Oruganti
, and Purandeswari Oruganti ![]() . Published on 12/09/25
. Published on 12/09/25
Introduction
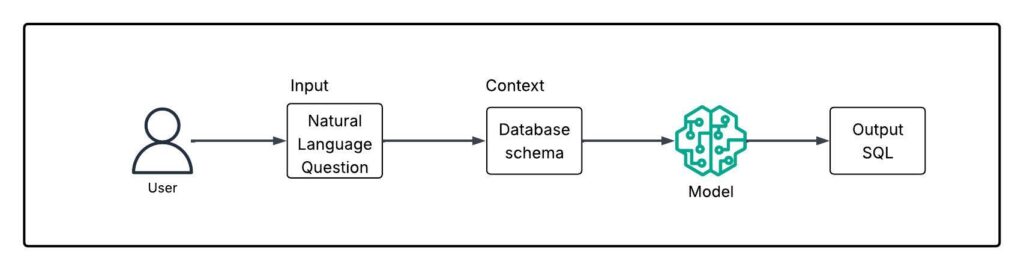
Large Language Models (LLMs) have rapidly advanced in their ability to understand and generate natural language, making them well-suited for structured tasks like SQL generation. In this project, several LLMs were utilized to build a text-to-SQL pipeline, including LLaMA 3.1–8B (QLoRA), Meta-Llama-3.1-70B-Instruct-AWQ-INT4, and Qwen2.5-Coder-32B-Instruct-GPTQ-Int4. The smaller 8B model was fine-tuned using QLoRA for low-resource adaptability, while the 70B model leveraged AWQ quantization for efficient inference. The Qwen model, pre-trained and instruction-tuned for code generation, was used out of the box, offering a strong baseline for comparison. Each model was chosen to assess how scale, fine-tuning methods, and architecture affect performance in translating natural language into accurate SQL queries.
The training and testing process was designed around a standardized database schema and a carefully curated dataset of natural language questions. The input queries covered a wide range of complexity—ranging from simple SELECT statements to more intricate JOINs and nested conditions. The models were not directly trained on this specific schema but were evaluated on their ability to generalize and reason through the structure based on instruction-following. The testing dataset consisted of over 150 prompts per model, ensuring a robust evaluation across varied SQL patterns and edge cases.
Performance was measured by analyzing the generated SQL outputs for both syntactic correctness and semantic accuracy. The LLaMA 3.1–8B (QLoRA) model achieved around 70% accuracy, reflecting some limitations in handling more complex queries. The 70B model (AWQ) performed significantly better, reaching 85–92% accuracy, thanks to its larger capacity and optimized quantization. However, the standout performer was the Qwen 2.5-Coder-32B-Instruct model, which achieved 95.73% accuracy, with minimal syntax or aliasing errors. It not only outperformed the other models but also surpassed GPT-4.5 Turbo, demonstrating the effectiveness of instruction-tuned code models for natural language to SQL translation.
Database
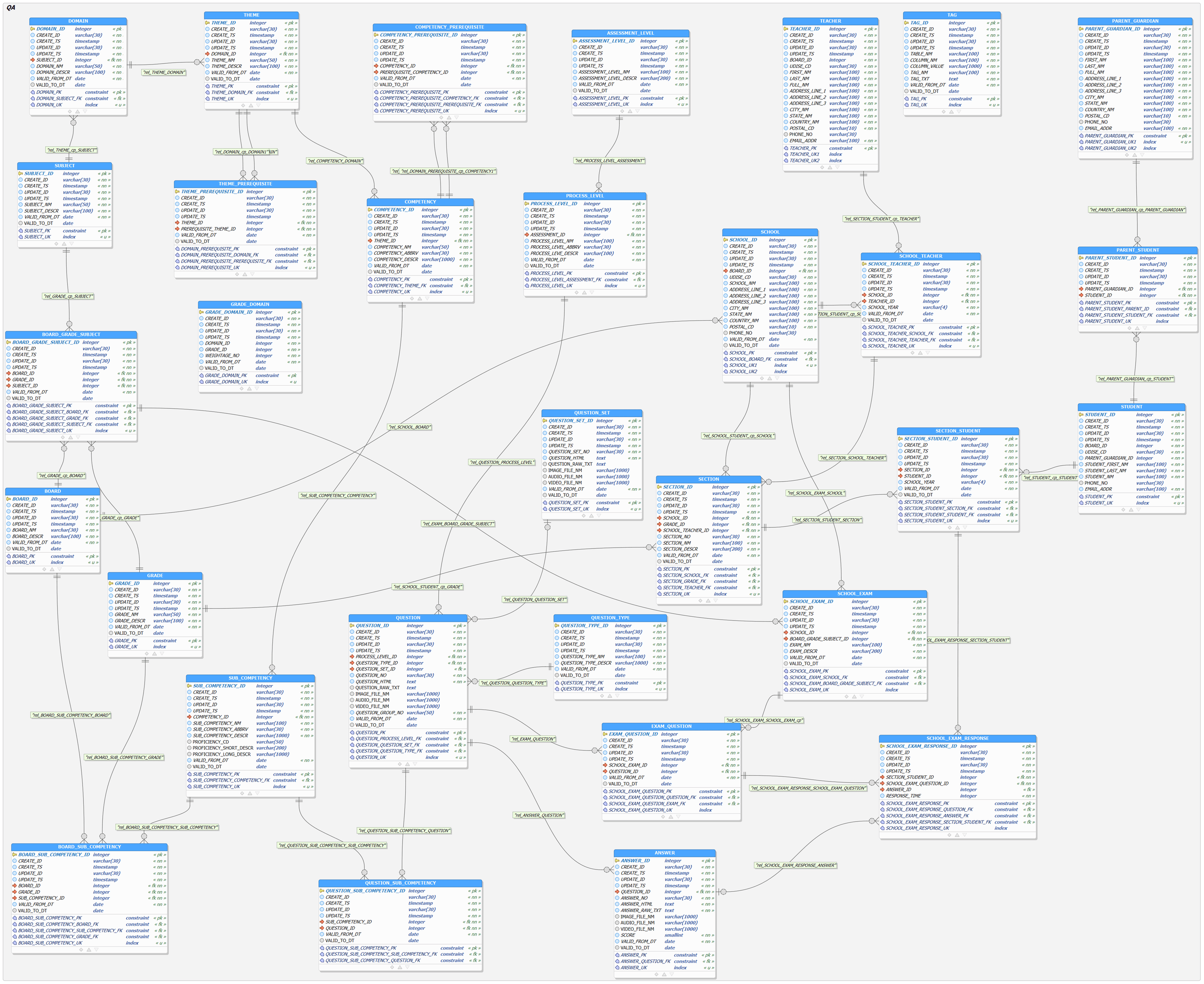
The database used in this project is a comprehensive and highly relational structure consisting of 31 interconnected tables. Each table is thoughtfully designed to represent distinct entities and real-world operations within a realistic business or application domain. The schema is reinforced by strong primary and foreign key relationships, which ensure referential integrity and consistency across the dataset. These constraints not only support complex transactional logic but also add an additional layer of difficulty for language models tasked with understanding and generating correct SQL queries. This robust relational design provides the foundation for testing how well models can reason through multi-table queries in a production-like environment.
Because of its depth, relational complexity, and diverse schema design, the database serves as a challenging benchmark for evaluating the semantic understanding of large language models (LLMs). Many of the queries involve multi-table JOINs, subqueries, aggregation, filtering, grouping, and the use of table aliases, requiring models to go beyond surface-level parsing and demonstrate true relational reasoning. The tightly linked nature of the tables means that even minor errors in table or column selection can lead to completely invalid queries. This structure played a crucial role in revealing not only how accurate each model was, but also how well they understood the underlying logic of the database when translating natural language into SQL.
Specifically, this database is designed for school management and includes tables such as board, schools, teachers, school-teacher relationships, students, and their parent or guardian information. Its design thoughtfully captures the complex relationships within educational institutions, including staffing, enrolment, and family connections. The database’s meticulous construction and comprehensive coverage of school operations make it an exceptionally robust and realistic environment for testing SQL generation models.
Context
In this project, the models were supplied with a detailed schema context that included the full structures of all database tables, their attributes, and the relationships between them. The database consists of 31 interconnected tables representing entities such as boards, schools, teachers, students, and guardians, along with their complex relational links. By explicitly providing primary keys, foreign keys, and table relationships, the models were given a comprehensive view of how entities connect in a school management domain.
Feeding this contextual information to the models was critical for enabling the models to generate syntactically correct and semantically accurate SQL queries, especially when handling multi-table JOINs, aggregations, and nested queries. By supplying the schema, the evaluation went beyond testing raw language capabilities and instead measured how well the models could reason over relational data. It revealed their ability to apply domain-specific logic in query generation, reducing errors in table and column selection while improving accuracy in complex query construction.
Below are 3 open source models that we tested for generating acurate SQLs.
1. LLaMA Fine-Tuning
meta-llama/Llama-3.1-8B-Instruct
The LLaMA (Large Language Model Meta AI) series, developed by Meta (FaceBook AI research), represents a powerful family of open-weight language models designed for efficiency and accessibility. The first version, LLaMA 1, was released in early 2023 and included models ranging from 7B to 65B parameters. It provided performance comparable to GPT-3 while being significantly smaller and more resource-efficient. However, it lacked instruction tuning and was not licensed for commercial use, making it more suitable for academic research and experimentation.
Building on that foundation, LLaMA 2 was released in mid-2023 with major upgrades. It introduced 7B, 13B, and 70B parameter models, along with instruction-tuned chat variants that were trained with reinforcement learning from human feedback (RLHF). These models demonstrated stronger alignment, better safety, and were released under a permissive license that allowed for commercial applications. LLaMA 2 quickly gained popularity in the open-source AI community, especially for fine-tuning using tools like PEFT, LoRA, and QLoRA.
The recent generation, LLaMA 3, was launched in 2024 with further enhancements. It features improved training datasets, support for longer context lengths, and significantly better performance— matching or even exceeding GPT-3.5 and approaching GPT-4 on various benchmarks. With models like the 8B and 70B variants, LLaMA 3 is optimized for multilingual capabilities, factual accuracy, and real-world deployment. These models are especially suited for custom fine-tuning across enterprise, educational, and research domains.
QLoRA
QLoRA (Quantized Low-Rank Adapter) is an efficient fine-tuning technique designed for large language models. It combines low-rank adaptation (LoRA) with 4-bit quantization to significantly reduce memory usage and computational cost, while maintaining model performance. QLoRA enables fine-tuning of large models on consumer-grade hardware, making advanced language model training more accessible.
Instead of fine-tuning all model parameters, small trainable adapter layers are added to specific parts of the network. The rest of the model is frozen (i.e., not updated during training). This enables efficient and fast training with fewer trainable parameters. You can find more about QLoRA in the references. We performed Llama 3 finetuning using QLoRA technique.
LORA CONFIGURATION:
- MODEL_NAME = "meta-llama/Llama-3.1-8B-Instruct"
- NUM_TRAIN_EPOCHS = 15
- PER_DEVICE_TRAIN_BATCH_SIZE = 1
- LEARNING_RATE = 2e-5
- LORA_R = 32
- LORA_ALPHA = 32
- LORA_DROPOUT = 0.1
- TARGET_MODULES = ["q_proj", "v_proj", "k_proj", "o_proj", "up_proj", "down_proj", "gate_proj"]
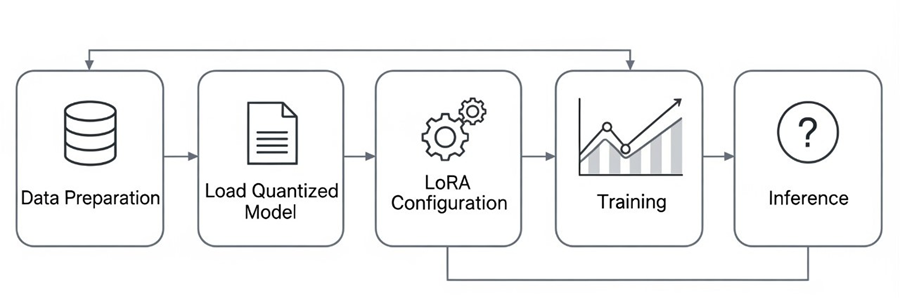
Fine-tuning large language models is often resource-heavy and time-consuming. QLoRA addresses this by using 4-bit quantization to reduce memory needs, enabling fine-tuning on consumer-grade GPUs. It updates only small adapter layers with LoRA, speeding up training and lowering costs. This makes customizing powerful models efficient without losing accuracy or requiring massive hardware.
Training Data
To train our Text-to-SQL models effectively, we first created the training data in a spreadsheet format (Excel/CSV). This allowed us to organize the dataset in a structured and scalable way, making it easy to expand, edit, and feed into the model during training. Using spreadsheets also gave us flexibility in labelling and categorizing examples, which proved helpful for evaluation and fine-tuning later.
The dataset was structured into several key columns: category, question, context, and answer. The category field was used to classify queries into easy, medium, and hard, based on their complexity. The question column contained the natural language input, while the context column provided schema details where required. Finally, the answer column held the corresponding SQL query for the question. This structure helped maintain consistency across the dataset and ensured that the model could learn from both simple and complex query patterns in a controlled way.
You can find some examples of training samples below...

Figure 3: Example 1 – “Easy Query” (Query of easy difficulty)

Figure 4: Example 2 – “Medium Query” (Query of medium difficulty)

Challenges
- Incorrect alias names by missing underscores, leading to invalid references.
- Misinterpreted the schema and attempted to use non-existent tables (e.g., using context instead of the domain table).
- Altered actual column names, such as changing postal_cd to postal_code or udise_cd to ud_sid.
- Omitted essential operators like ILIKE for string search conditions.
- Misformatted column names by dropping underscores, for example turning city_nm into citynm.
These consistent issues demonstrated the model’s difficulty in adhering to strict schema definitions and SQL conventions, making fine-tuning a necessary step to improve accuracy and reliability.
Test Results
To evaluate accuracy, we tested each sample by comparing the model’s generated SQL query against the expected output. A query was marked as “accurate” or “pass” only if it both produced the correct expected result and contained no syntax errors. If either condition failed—such as an incorrect result or a query that could not execute due to syntax issues—the sample was classified as “inaccurate” or “fail”. This strict evaluation method ensured that accuracy truly reflected the model’s ability to generate valid and semantically correct SQL queries.
The test results for the Meta LLaMA 3.1–8B model fine-tuned with QLoRA demonstrate a solid performance on SQL query generation tasks. Out of 173 test prompts, the model successfully generated correct outputs for 122 prompts, resulting in a pass rate of 70.8%.
This indicates that while the model was able to handle most prompts accurately, there were 51 instances where the generated queries were incorrect or incomplete, highlighting areas for improvement. Overall, these results reflect the effectiveness of QLoRA fine-tuning in enhancing the LLaMA 8B model’s ability to generate structured and contextually accurate SQL queries, while also pointing to potential limitations in handling edge cases or complex query structures.




2. LLaMA AWQ
Meta-Llama-3.1-70B-Instruct-AWQ-INT4
LLaMA 3.1–70B is one of the most powerful open-source language models released to date, developed by Meta with an impressive 70 billion parameters. Built on a decoder-only transformer architecture, it delivers state-of-the-art performance across a wide range of natural language processing tasks, from reasoning and coding to multilingual understanding and content generation. Unlike closed models, LLaMA 3.1–70B is openly available for research and non-commercial use, making it a valuable resource for developers, researchers, and AI enthusiasts.
One of the standout features of Meta-Llama-3.1-70B-Instruct-AWQ-INT4 is its 128,000-token context window, which allows it to process and retain extremely long inputs such as documents, chat histories, or contracts without fragmentation. Combined with an improved tokenizer, optimized memory handling, and grouped-query attention, the model achieves better efficiency and scalability even at such a large capacity. These refinements make it not only powerful but also practical for real-world deployment.
In comparison to smaller siblings like the 8B variant, LLaMA 3.1–70B demonstrates far superior accuracy, coherence, and reasoning ability, making it particularly well-suited for enterprise applications such as retrieval-augmented generation (RAG), document summarization, large-scale content generation, and translation.
AWQ
Activation-aware Weight Quantization (AWQ) is an advanced technique used to reduce the memory footprint and computational cost of large language models without significantly sacrificing accuracy. Unlike traditional quantization methods, which uniformly compress all weights, AWQ considers the activation distribution of each layer during quantization. By adapting the precision of weights based on how activations propagate through the network, AWQ can preserve the dynamic range and reduce errors that would otherwise accumulate in low-precision computations.
When applied to LLaMA models, AWQ allows even very large variants, such as LLaMA 3.1–70B, to be run on hardware with limited memory or to accelerate inference without the full computational overhead. The technique effectively compresses model parameters while maintaining accuracy in reasoning, generation, and complex tasks. However, fine-tuning or applying AWQ requires careful calibration: improper quantization can introduce subtle errors, especially in tasks that depend on precise numerical relationships, such as SQL query generation. Overall, AWQ strikes a balance between efficiency and performance, enabling large LLaMA models to be deployed more practically in both research and production environments. You can find more about AWQ in the references.
Challenges
- Not picking the correct schema name.
- Not retrieving the correct column names.
- Not using the ILIKE operator, even though all training samples consistently used it.
- Generating queries with asterisk (*) instead of explicitly listing column names, as shown in the training samples.
- Confusing one table’s columns with another.
While using Meta-Llama-3.1-70B-Instruct-AWQ-INT4 model, we encountered several challenges that affected the accuracy of generated SQL queries. The model often failed to correctly identify the schema name and sometimes returned incorrect column names. Despite all training samples using the ILIKE operator, the model occasionally omitted it, producing queries that would fail in practice. Similarly, it sometimes generated asterisks (*) instead of listing explicit column names, even though training examples consistently specified the required columns. Another recurring issue was confusing columns from one table with those of another, leading to invalid or mismatched queries. These challenges highlight that, although AWQ improves memory efficiency and inference speed, it can also amplify subtle generation errors if not carefully fine-tuned.
Test Results
The table presents the evaluation results for the Meta-Llama-3.1-70B-Instruct-AWQ-INT4 model utilizing AWQ (Activation-aware Weight Quantization). The model was tested on a total of 207 prompts, out of which it successfully passed 191 and failed 16, resulting in an overall accuracy of 92.00%. Compared to earlier models, most of the previously observed challenges—such as incorrect schema usage, wrong column names, missing ILIKE operators, and overuse of asterisks—were significantly reduced in this version, highlighting clear progress in performance and reliability. This demonstrates that fine-tuning and quantization not only improved efficiency but also enhanced consistency in generating correct SQL queries. These results reflect the model's strong performance in handling a diverse set of test prompts while benefiting from quantization optimizations that improve efficiency without significantly impacting accuracy.



3. Qwen Instructor Coder
Qwen/Qwen2.5-Coder-32B-Instruct-GPTQ-Int4
The Qwen/ Qwen2.5-Coder-32B-Instruct-GPTQ-Int4 model is a powerful instruction-tuned language model developed specifically for complex reasoning and code-related tasks. Built on the Qwen 2.5 architecture, this 32-billion parameter model has been optimized to follow instructions, generate accurate code, and perform a wide range of natural language processing tasks. It supports multiple programming languages and demonstrates strong performance in code synthesis, code completion, and problem-solving benchmarks. The "Instruct" tuning makes it particularly effective in responding to user queries with high relevance and coherence, making it a competitive choice in both coding and general-purpose AI applications.
In performance testing, Qwen2.5-Coder-32B-Instruct-GPTQ-Int4 model has consistently outperformed several other leading models, including both smaller and larger parameter models. Even when quantized to more efficient formats like Int4, it maintains exceptional accuracy and reliability, making it well-suited for deployment in resource-constrained environments without sacrificing performance. Its ability to strike a balance between computational efficiency and output quality has made it a top performer in recent benchmarks, particularly in instruction-following and developer-focused use cases.
Challenges
The Qwen 2.5-Coder-32B-Instruct model has significantly addressed many of the limitations previously observed in models like LLaMA 3.1-8B and Meta-Llama-3.1-70B-Instruct-AWQ-INT4. Issues such as syntax errors, aliasing mistakes, and inconsistent formatting—common in earlier models—were notably absent in Qwen’s outputs. Its instruction-following capabilities and understanding of code structure have been markedly superior, resulting in more accurate and production-ready code completions.
However, a few challenges persisted. In some cases, the model selected incorrect column names or referenced the wrong tables, particularly in complex SQL generation tasks. These types of semantic errors, while less frequent, suggest that there is still room for improvement in contextual understanding of database schema and intent. Nonetheless, the absence of lower-level mistakes like syntax and aliasing errors marks a clear step forward in reliability and usability compared to earlier models.
Test results
The Qwen 2.5-Coder-32B-Instruct-GPTQ-Int4 model delivered outstanding performance, clearly outperforming all other models in the evaluation. With an impressive accuracy of 95.73%, it set a new benchmark in our testing pipeline. Compared to other models, its lead wasn’t marginal—it surpassed its closest competitors by a significant margin, demonstrating superior consistency, code reliability, and instruction adherence.



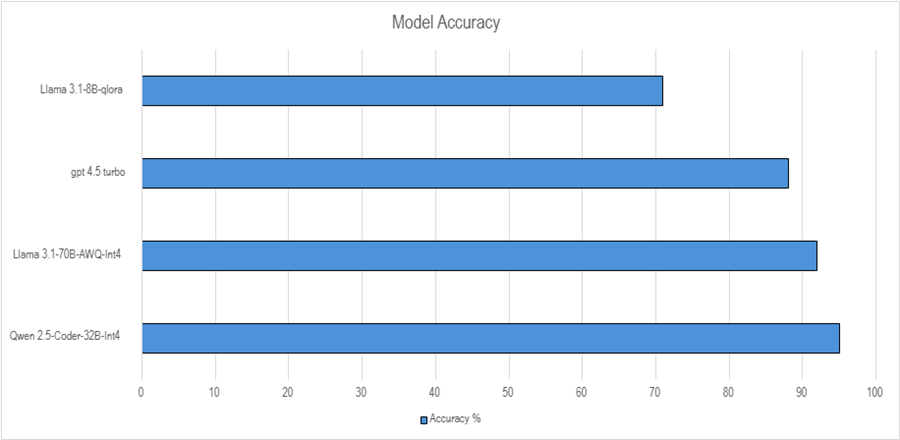
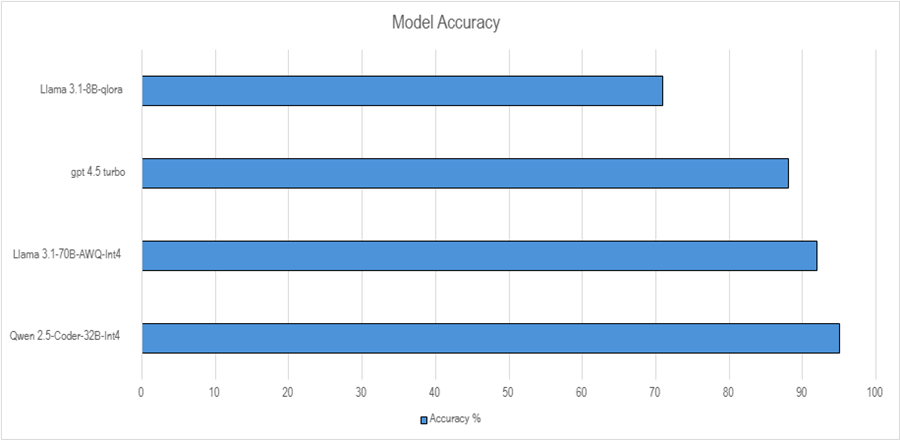
Results Comparison
As shown in the chart titled "Model Accuracy", several LLM models were evaluated for performance across a standardized test set. The LLaMA 3.1-8B-qLoRA model had the lowest accuracy among the group, scoring just above 70%. Moving up, GPT-4.5 Turbo showed a significant improvement, achieving close to 90% accuracy, indicating strong general performance. Meta-Llama-3.1-70B-Instruct-AWQ-INT performed even better, reaching slightly over 92%, demonstrating that quantized versions of large models can still deliver high accuracy while being more resource efficient.
At the top of the chart, Qwen 2.5-Coder-32B-Instruct-GPTQ-Int4 emerged as the best-performing model, slightly edging out the others with the highest accuracy of just under 95%. This shows that Qwen 2.5-Coder not only handles coding and general tasks well but also maintains strong performance even when quantized to Int4, which typically trades off some precision for speed and memory efficiency. Overall, while all models performed respectably, Qwen 2.5-Coder-32B-Instruct stood out as the most accurate in this comparison.
References
- Llama-3.1-8B-Instruct
- Meta-Llama-3.1-70B-Instruct-AWQ-INT4
- Qwen2.5-Coder-32B-Instruct-GPTQ-Int4
- Quantized Low Rank Adaptation (QLoRA)
- Activation-aware Weight Quantization (AWQ)
- GPTQ
Good article. Really appreciate the insights.