
Maximizing Accuracy with VLMs: Replacing OCR Pipelines with Pydantic Structured Outputs
Authors: Vivek Krishnamoorthy ![]() , M Harshavardhan Reddy
, M Harshavardhan Reddy ![]() , and Purandeswari Oruganti
, and Purandeswari Oruganti ![]() . Published on 02/09/26
. Published on 02/09/26
The shift from traditional OCR to Vision-Language Models (VLMs) is fundamentally redefining document intelligence. To ensure the integrity of our results and avoid the "data contamination" common in standard benchmarks, we avoided public datasets entirely. Our evaluation was conducted using a custom corpus of proprietary layouts and real-world documents that these models have never encountered during their training phases. This provides a true measure of their "out-of-distribution" performance, proving that the future of extraction lies in raw visual reasoning, not pattern memorization.
1. The Challenge: Why Traditional OCR Fails
Modern corporate documents often feature a multi-tiered information architecture that defies simple tabular reading.
- Nested Hierarchies: Documents often feature complex nested grids where high-level categories branch into multiple sub-columns. A single primary column might act as an "umbrella" for distinct attributes like codes and revision statuses packed side-by-side.
- Three-Dimensional Relationships: Interpreting a single cell often requires the model to trace relationships vertically through layers of nested headers and horizontally to its governing row group.
- Dynamic Partitioning: Real-world schemas are rarely uniform; vertical partition lines—the "visual anchors" that dictate where one field ends—can vary row by row. Traditional OCR often fails to recognize these shifting visual boundaries as logical delimiters.
- Orphaned data: When high-density document structures, such as nested tables or complex row groups, extend seamlessly across physical page boundaries. Because a data category initiated on one page often spills over to the next without repeating the full hierarchy of headers or parent identifiers, traditional parsers often lose the logical link between the data and its context. This results in fragmented or "orphaned" rows that lack their defining structural definitions.
Example complex document layout:
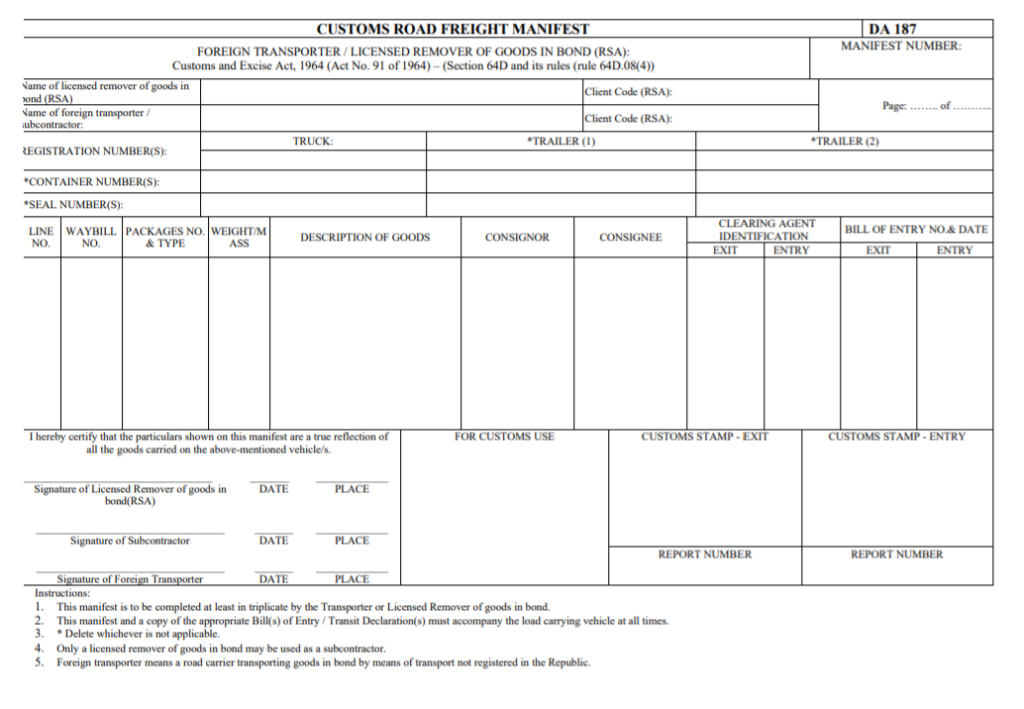
Engineering document
2. The Ingestion Pipeline: Precision vs. The "Density Tax"
To bridge the gap between a static PDF and a dynamic JSON output, we employ a high-fidelity ingestion pipeline using the pdf2image library. By leveraging the convert_from_path method backed by Poppler, each document page is transformed into a raw image buffer. This stage is where we fine-tune the "visual acuity" of the system, a decision that has a direct impact on the model's ultimate accuracy and resource consumption DPI Calibration: While 300 DPI suffices for standard text, 600 DPI is often necessary to resolve microscopic details in dense technical forms.
DPI Calibration and "Visual Acuity"
The resolution of the input image, measured in Dots Per Inch (DPI), is the primary lever for controlling extraction quality.
- 300 DPI: A standard 8.5 x 11-inch page results in approximately 2,550 x 3,300 pixels, totaling roughly 8.4 million pixels. While 300 DPI is often sufficient for standard text layouts, it may fail to resolve the fine details required for complex extraction.
- 600 DPI: Doubling the resolution to 600 DPI results in 5,100 x 6,600 pixels, totaling roughly 33.6 million pixels. Bumping the resolution to 600 DPI allows the model to resolve microscopic details in dense technical forms or multi-nested tables.
- This higher resolution is essential for models like Gemini 3-Pro-Preview to accurately identify visual whitespace and alignment as clear structural signals.
The Mechanics of Dynamic Tiling
Advanced VLMs process these high-resolution images through a method called dynamic tiling or "patching"
- Instead of analyzing the image as a single block, the architecture divides it into a grid of smaller patches, typically sized at 768 X 768 or 512 X 512 pixels
- The model treats each tile as a specific area of focus, looking at the document through a "high-powered magnifying glass" while maintaining a global coordinate map of the entire page.
- As the DPI increases, the total pixel count grows, leading to a higher number of patches created by the vision encoder.
The "Density Tax": Balancing Performance and Cost
This granular approach to vision introduces a critical engineering trade-off known as the density tax
- Each individual patch is assigned a fixed number of tokens—often around 258 tokens per tile in Gemini architectures.
- Consequently, a 600 DPI image can easily consume four times as many tokens as a 300 DPI version.
- This increased "visual payload" forces the model's attention mechanism to process a much larger data volume, which directly correlates to longer generation latency and higher compute costs.
- For models billed on a per-token basis, failing to find the "sweet spot" in DPI settings can quickly exhaust context windows or lead to unsustainable costs.
3. Architectural Strategies: Single vs. Multi-Page Context
As we transition from experimentation to deploying large-scale Vision-to-JSON pipelines, managing token consumption becomes as critical as model accuracy. Because high-resolution image inputs consume a significant portion of the token budget, we have adopted a dual-track strategy: Single-Page and Multi-Page context. This allows us to tailor the model’s processing power to the specific structural needs of a document.
The Single-Page Approach: Maximum Precision
In this strategy, each page is processed as an individual, high-resolution visual unit.
- Isolation of Focus: By isolating one page at a time, we inject a highly specific set of instructions and the target JSON schema alongside every single image sent to the model.
- Eliminating Context Dilution: This prevents "context dilution," a common issue where large models lose track of fine details when overwhelmed by too much data at once.
- High Performance: This has proven to be the most high-performing mode, delivering the highest level of textual and structural precision for dense table rows and complex visual anchors.
- The "Instruction Repetition" Tax: Interestingly, this method often accumulates a much higher total token count. Because the full system prompt and schema are resent with every individual image, the "instruction repetition" causes the token count to climb faster than expected, making it the more expensive and higher-latency path.
The Multi-Page Approach: Global Continuity
In contrast, the Multi-Page Context strategy sends the system prompt, instructions, JSON schema, and all relevant page images simultaneously in a single request.
- Global View: This method provides the VLM with a "global" view of the document, which is particularly useful for linking data that spans across pages.
- Token Efficiency: Because instructions are sent only once, the overall token consumption is far more efficient. Side-by-side audits revealed startling cost savings compared to the Single-Page mode.
- The Accuracy Trade-off: This efficiency introduces a notable risk: the model is more susceptible to "context dilution." As the focus drifts away from the initial schema and guidelines provided at the start, the model may lose the "keen eye" for detail it exhibits when locked onto an isolated page.
Ultimately, the choice depends on the stakes: for production workflows where accuracy is non-negotiable, the extra cost of the Single-Page approach is often justified by the near-perfect alignment of the resulting Pydantic Object.
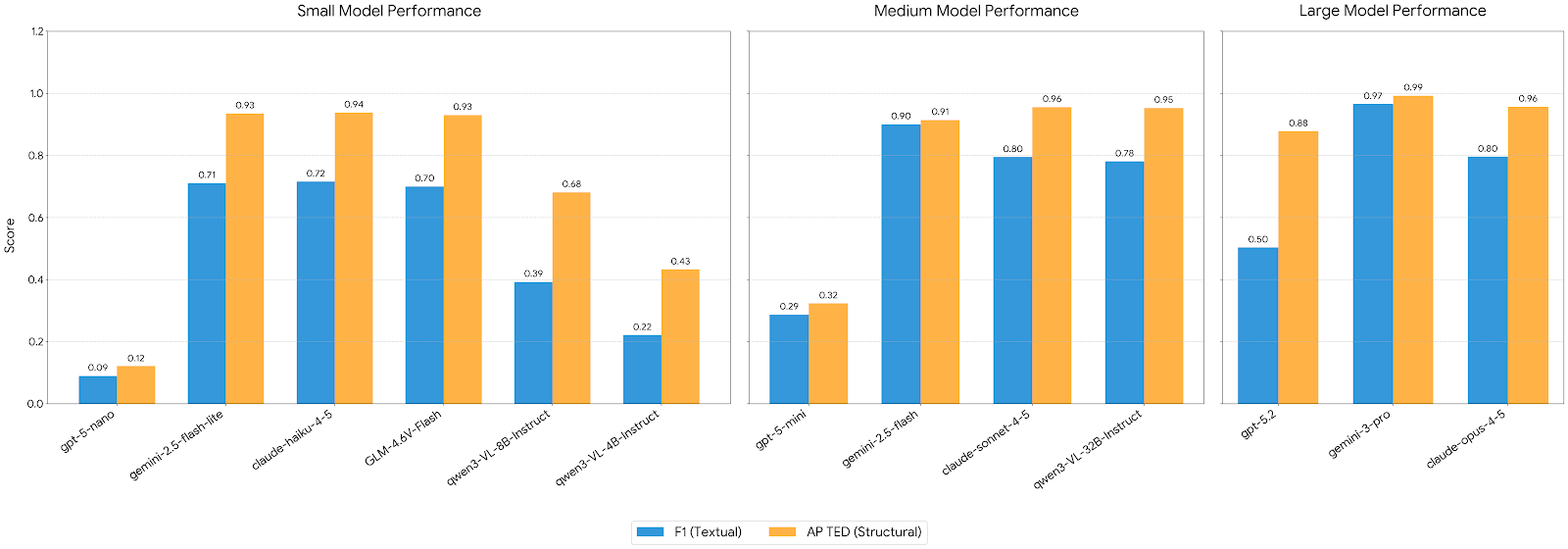
4. Model Performance Comparison
Our evaluation reveals a clear "performance floor" dictated by the architectural scale of Vision-Language Models. While many models can process simple linear forms with ~70-80% accuracy, production-grade automation requires the high-dimensional reasoning found only in top-tier architectures.
| Tier | Model Name | Precision | Recall | F1 | APTED | ZSS | Latency (s) | Prompt Tokens | Context Tokens | Total Input Tokens | Output tokens |
| Small | gemini-2.5-flash-lite | 0.7132 | 0.7077 | 0.7104 | 0.9347 | 0.9347 | 26.25 | 37.5k | 7.1k | 44.6k | 7k |
| claude-haiku-4-5 | 0.7146 | 0.7173 | 0.7159 | 0.9376 | 0.9376 | 38.6 | 37.8k | 7.0k | 44.8k | 6.9k | |
| qwen3-VL-8B-Instruct | 0.5206 | 0.3154 | 0.3928 | 0.6813 | 0.6813 | 172.71 | 51.8k | 3.8k | 55.6k | 4k | |
| qwen3-VL-4B-Instruct | 0.4606 | 0.1462 | 0.2219 | 0.4331 | 0.4331 | 94.94 | 51.8k | 2.2k | 53.9k | 2k | |
| gpt-5-nano | 0.7143 | 0.0481 | 0.0901 | 0.1214 | 0.1214 | 125.5 | 30.9k | 15.7k | 46.6k | 15k | |
| GLM-4.6V-Flash | 0.70 | 0.69 | 0.70 | 0.93 | 0.92 | 469 | 37k | 13k | 50k | 12.6k | |
| Medium | gemini-2.5-flash | 0.8937 | 0.9058 | 0.8997 | 0.9139 | 0.9139 | 87.47 | 37.5k | 7.1k | 56.8k | 7.1k |
| claude-sonnet-4-5 | 0.7946 | 0.7962 | 0.7954 | 0.9553 | 0.9553 | 79.87 | 37.8k | 6.9k | 44.7k | 6.8k | |
| qwen3-VL-32B-Instruct | 0.7808 | 0.7808 | 0.7808 | 0.9528 | 0.9528 | 779.69 | 51.8k | 6.0k | 57.7k | 5.9k | |
| gpt-5-mini | 0.7913 | 0.175 | 0.2866 | 0.3236 | 0.3236 | 146.87 | 30.1k | 8.9k | 38.9k | 8.8k | |
| Large | gemini-3-pro | 0.9654 | 0.9654 | 0.9654 | 0.9925 | 0.9925 | 267.65 | 33.0k | 7.1k | 60.2k | 7k |
| claude-opus-4-5 | 0.7962 | 0.7962 | 0.7962 | 0.9561 | 0.9561 | 73.86 | 37.8k | 6.8k | 44.6k | 6.8k | |
| gpt-5.2 | 0.5058 | 0.5019 | 0.5039 | 0.8779 | 0.8779 | 137.62 | 30.1k | 4.8k | 34.8k | 4.7k |
5. Measuring Success: The Dual-Metric System
Evaluating the accuracy of Pydantic objects generated by Vision-Language Models (VLMs) requires a multidimensional approach. Traditional text-based metrics often fail to capture the structural complexity, while structural-only metrics might ignore the precision of the extracted data. Therefore, we utilize a standardized scoring range of 0 to 1 to aggregate textual, structural, and temporal performance. We convert Pydantic objects to JSON and calculate the below scores.
F1 Score: Textual and Semantic Accuracy
The F1 Score serves as our primary measure for ensuring the model captures all required information (recall) without "hallucinating" extra fields (precision).
- Precision: Measures the ratio of correctly identified JSON keys and values to the total items generated, ensuring the model is not fabricating data.
- Recall: Evaluates "thoroughness" by calculating the proportion of actual data points in the PDF successfully captured in the JSON.
- The Harmonic Mean: Calculated as:
F1 Score = 2 * (Precision * Recall) / (Precision + Recall)
A high F1 score confirms "Optimal Extraction," where every entry is both present and semantically correct.
Structural Integrity: AP TED & ZSS
While textual metrics confirm what was found, structural metrics evaluate where it was placed within the hierarchy.
AP TED (All Path Tree Edit Distance):
The All Path Tree Edit Distance (AP TED) is a structural metric that calculates the mathematical "cost" required to transform the model's generated JSON tree into the "ground-truth" (perfect) JSON tree.
How it works: It looks at the nesting and spatial relationships of the document.
The Score: A score of 1.0 represents a perfect structural match where every parent-child relationship is exactly where it should be.
The Goal: A high AP TED score confirms the model correctly understood the layout—for example, it didn't accidentally put a row from "Table B" inside the header for "Table A".
ZSS Score (Zhang-Shasha Score):
The ZSS Score is an algorithm that focuses on the specific logical flow of the JSON.
How it works: It counts the minimal number of node operations—insertions, deletions, or substitutions—required to make the model's output match the target structure.
The Goal: It acts as a robust verification of hierarchical integrity. If a model "hallucinates" an extra nested level or skips a category, the ZSS score will drop because more "operations" are needed to fix the tree.
Conclusion: The New Era of Document Intelligence
The Vision to Structured Output workflow represents a fundamental shift in how we handle complex data, moving away from fragmented, multi-stage OCR pipelines toward a unified, end-to-end extraction process. By processing documents as a single visual tensor, Vision-Language Models (VLMs) can simultaneously recognize characters and interpret their spatial context. This holistic view allows them to master elements that have long baffled standard parsers, such as nested tables, multi-column layouts, and intricate visual hierarchies.
What's Next:
While VLM-to-Pydantic extraction marks the end of legacy OCR pipelines, the journey doesn't stop at structured data. Stay tuned for our next deep dive into Agentic Vision, where we explore how VLMs use internal 'thinking' loops and code execution to investigate documents with human-level precision.