
Building a Configuration-Driven ETL Orchestrator with AWS Step Functions
Authors:
Giri Appalaneni
![]() ,
Sai Belaganti
,
Sai Belaganti
![]()
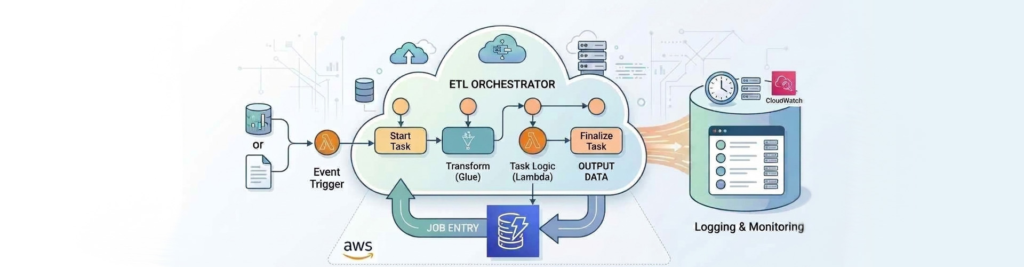
In modern data engineering, hardcoding workflow logic is a recipe for maintenance of headaches. I recently built a flexible, event-driven orchestration engine using AWS Step Functions, AWS Lambda, and Amazon DynamoDB to manage Glue jobs dynamically.
This approach shifts the control logic from code to a metadata-driven configuration, allowing us to manage job schedules and dependencies without redeploying our infrastructure.
The Architecture at a Glance
The solution uses a “Control Table” pattern where DynamoDB acts as the brain, Step Functions as the nervous system, and Glue as the muscle.
- Metadata Layer (DynamoDB): Stores job definitions including JobName, Environment, JobCategory, RunCondition (e.g., “Monday, Wednesday”), SkipFlag, and StatusFlag.
- Orchestration (Step Functions): Coordinates the flow, handles retry and manages parallel execution.
- Compute Logic (Lambda): A specialized “Checker” function that evaluates the RunCondition against the current system in time to decide if a job should execute.
Step-by-Step Workflow
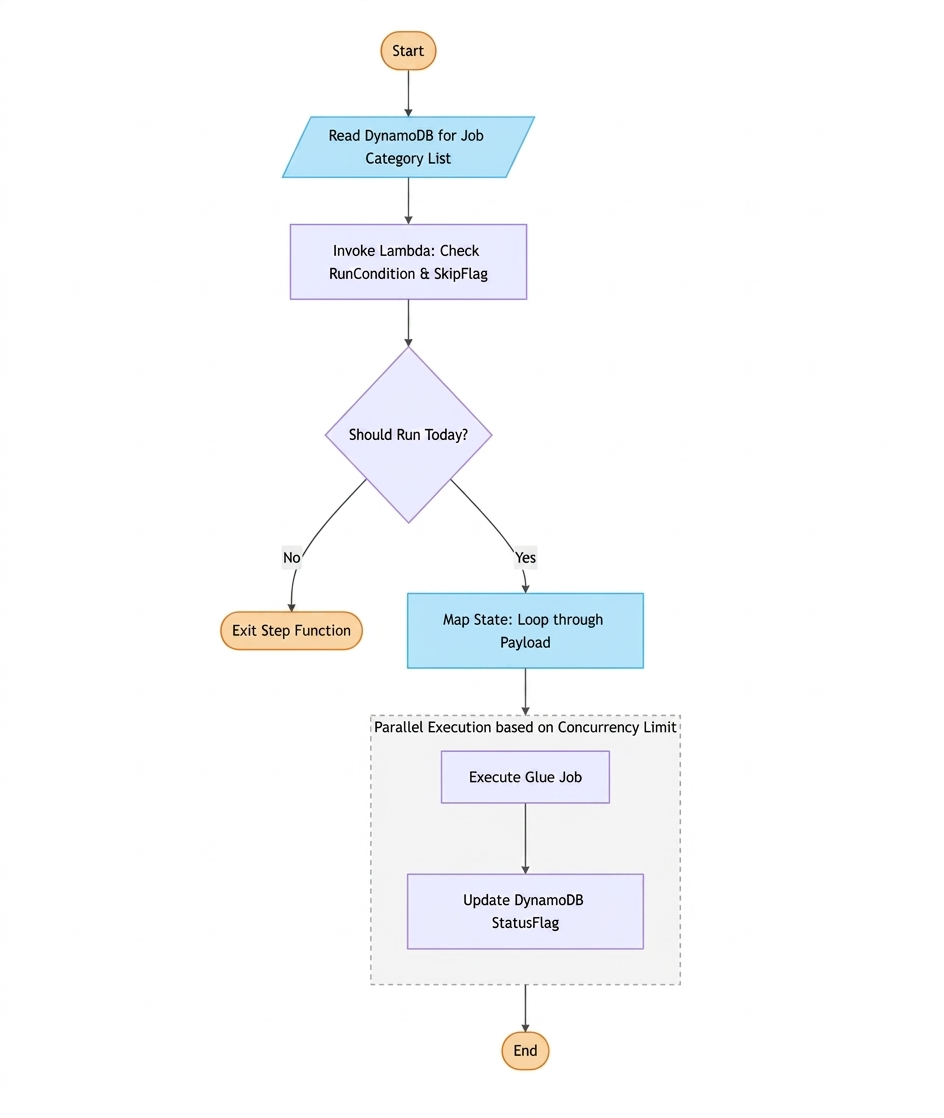
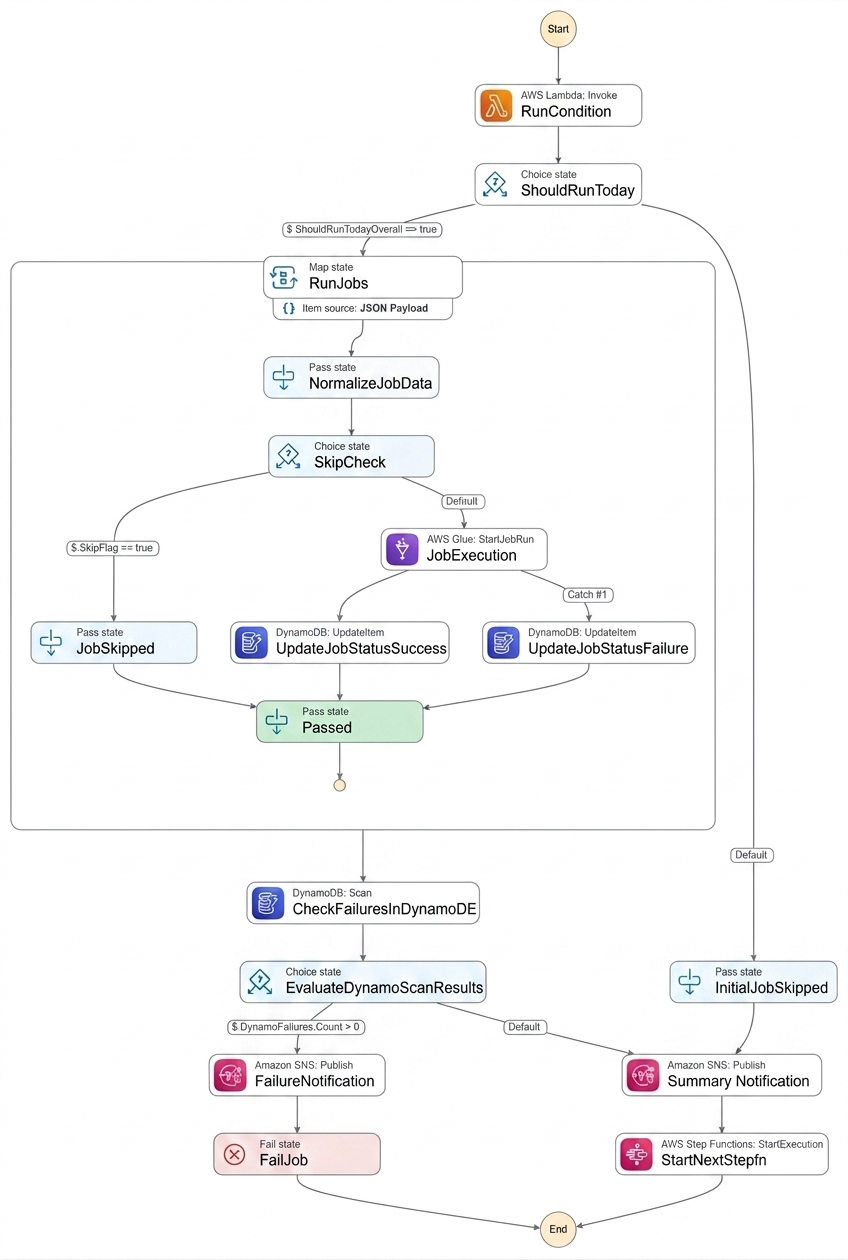
1. Fetching the Job Catalog
When the Step Function starts, its first task is to read from DynamoDB. Based on an input JobCategory, it performs a query to retrieve all associated Glue jobs. This allows us to group related ETL tasks (e.g., “Daily_Sales” or “Monthly_Finance”) into a single execution.
2. The Smart Filtering Lambda
For every job retrieved, the workflow invokes a Lambda function to perform a “pre-flight check.” This Lambda is critical for two reasons:
- Time-Based Logic: It checks the RunCondition. If a job is marked for “Monday” and today is Tuesday, the Lambda returns ShouldRunToday: false.
- Manual Overrides: It checks the SkipFlag. If an administrator has set this to “Yes” (perhaps due to a known upstream data issue), the job is bypassed.
The Lambda returns a unified payload:
json {
“JobName”: “my_glue_job”,
“RunCondition”: “Monday, Wednesday”,
“SkipFlag”: “No”,
“ShouldRunToday”: true
}
3. Dynamic Parallelism and Execution
If the workflow determines whether a job should run, it enters a Map state. This is where the magic of dynamic parallelism happens:
- Looping: The Step Function iterates through the payload of jobs flagged as ShouldRunToday.
- Concurrency Control: To prevent overwhelming our Glue service quotas or the source database, we set a MaxConcurrency limit within the Map state.
- Glue Invocation: The Step Function uses the optimized integration to start the Glue job and waits for a success or failure callback.
Key Technical Benefits
- Zero-Code Scheduling: To change jobs from daily to weekly, you simply update a row in DynamoDB—no code changes required.
- Operational Resilience: By checking the SkipFlag at runtime, we can “pause” specific parts of our pipeline instantly during maintenance windows.
- Visual Debugging: Since Step Functions provides a visual execution map, we can instantly see which specific Glue job failed and why, directly from the console.
High-Level Architectural Flow of the Orchestration Engine
Sample Definition:
Summary of DynamoDB Schema
| Attribute | Description |
| JobName | The unique identifier for the Glue job. |
| JobCategory | Grouping key (e.g., Marketing, Finance). |
| RunCondition | When the job should run (e.g., “Monday” or “ALL_DAYS”). |
| SkipFlag | Boolean to manually bypass a job run. |
| StatusFlag | Tracks the last known state (Success/Failure) for operations teams. |
This architecture has significantly reduced our deployment frequency and given our operations team more control over the ETL lifecycle.
Sample Dynamo DB Table:
| JobName (Partition Key) | JobCategory | RunCondition | SkipFlag | StatusFlag | LastRunTimestamp |
| JOB1 | RAW | MONDAY,TUESDAY | NO | success | 2026-10-25-T08:00:00Z |
| JOB2 | RAW | MONDAY,TUESDAY | NO | success | 2026-10-25-T08:30:00Z |
| JOB3 | STG | YES |
Conclusion: The Power of Metadata-Driven Orchestration
By decoupling our workflow logic from the underlying code, we have built an orchestration engine that is as flexible as it is powerful. Using AWS Step Functions as our backbone and Amazon DynamoDB as our configuration brain, we’ve achieved:
- Agility & Speed: Integrating or modifying a job schedule no longer requires a code deployment—just a simple row update in DynamoDB.
- Operational Transparency: The visual interface of Step Functions allows our team to monitor thousands of parallel jobs and debug failures instantly.
- Scalable Efficiency: Dynamic parallelism and concurrency limits ensure our data pipelines scale reliably without hitting service quotas or overwhelming source databases.
Future Improvements: Scaling the Engine
While this framework solves our immediate needs, we are already looking at ways to enhance its capabilities:
- Real-time Status Dashboards: We aim to build a lightweight front-end portal that reads the StatusFlag from DynamoDB in real-time, providing our non-technical stakeholders with a “heartbeat” view of our data health.
- AI-Driven Anomaly Detection: Integrating Amazon SageMaker to analyze job runtimes stored in DynamoDB could help us proactively identify performance bottlenecks or “stuck” jobs before they impact downstream reporting.